Introduction
With the rapid adoption of Apache Hadoop, enterprises use machine learning as a key technology to extract tangible business value from their massive data assets. This derivation of business value is possible because Apache Hadoop YARN as the architectural center of Modern Data Architecture (MDA) allows purpose-built data engines such as Apache Tez and Apache Spark to process and iterate over multiple datasets for data science techniques within the same cluster.
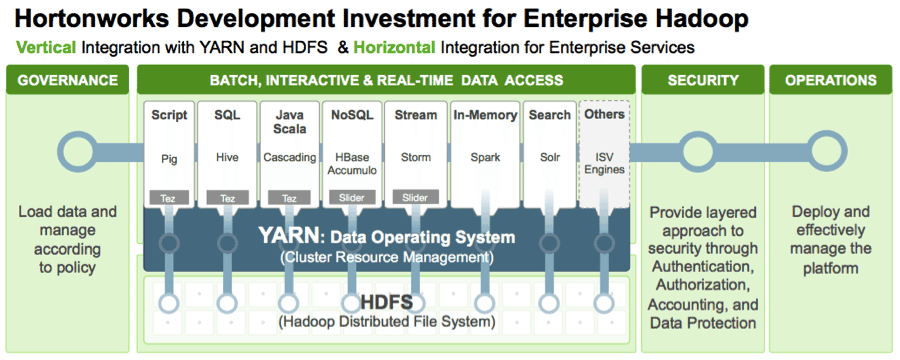
It is a common misconception that the way data scientists apply predictive learning algorithms like Linear Regression, Random Forest or Neural Networks to large datasets requires a dramatic change in approach, in tooling, or in usage of siloed clusters. Not so: no dramatic change; no dedicated clusters; using existing modeling tools will suffice.
In fact, the big change is in what is known as “feature engineering”—the process by which very large raw data is transformed into a “feature matrix.” Enabled by Apache Hadoop with YARN as an ideal platform, this transformation of large raw datasets (terabytes or petabytes) into a feature matrix is now scalable and not limited by RAM or compute power of a single node.
Since the output of the feature engineering step (the “feature matrix”) tends to be relatively small in size (typically in the MB or GB scale), a common choice is to run the learning algorithm on a single machine (often with multiple cores and high amount of RAM), allowing us to utilize a plethora of existing robust tools and algorithms from R packages, Python’s Scikit-learn, or SAS.
In this multi-part blog post, we will demonstrate an example step-by-step solution to a supervised learning problem. We will show how to solve this problem with various tools and libraries and how they integrate with Hadoop. In part I we focus on Apache PIG, Python, and Scikit-learn, while in subsequent parts, we will explore and examine other alternatives such as R or Spark/ML-Lib
Cluster Configuration
For all the examples using machine techniques in this series, we employed a small Hortonworks Data Platform (HDP) cluster with the following configuration:
- 4 Nodes
- Each node with 4 cores and 16GB RAM and 500GB disk space
- Each node runs CentOS 6 and HDP 2.1
Pig and Python Can’t Fly But Can Predict Flight Delays
Every year approximately 20% of airline flights are delayed or cancelled, resulting in significant costs to both travelers and airlines. As our example use-case, we will build a supervised learning model that predicts airline delay from historical flight data and weather information.

We start by exploring the airline delay dataset available here. This dataset includes details about flights in the US from the years 1987-2008. Every row in the dataset includes 29 variables (which you can peruse from the link below).
The detailed step-by-step construction of the feature matrix, machine learning model, implementation details as well as the model evaluation steps are shown in the IPython notebook here.
You can follow the notebook example or re-run it on your own cluster and IPython instance.
This IPython notebook demonstrates:
- Exploring the raw data to determine various properties of features and how predictive these features might be for the task at hand.
- Using PIG and Python to prepare the feature matrix from the raw data. We perform 3 iterations. With each iteration, we improve our feature set, resulting in better overall predictive performance. For example, in the 3rd iteration, we enrich the input data with weather information, resulting in predictive features such as temperature, snow conditions, or wind speed. This iterative nature of data science is a very common practice.
- Using Python’s Scikit-learn, we build various models, such as Logistic Regression or Random Forest. The feature matrix fits in memory (as is usually the case), so we run this locally on a local machine with 16 GB of memory.
- Using Scikit-learn, we evaluate performance of the models and compare between iterations.
Summary
In this blog post we demonstrated how to build a predictive model with Hadoop and Python using open source tools. We employed Hadoop to perform various types of data pre-processing and feature engineering tasks, followed by applying Scikit-learn machine learning algorithm on the resulting datasets. In addition, we showed how we could continuously add new and improved features to obtain a better predictive performance model by doing iterations and by introducing various variables with predictable results.
In the next part of this multi-part blog post, we will show how to perform the same learning task with Spark and ML-Lib.
Learn More
The post Data Science with Apache Hadoop: Predicting Airline Delays appeared first on Hortonworks.